Además de un friki de los ordenadores, soy un lector bastante compulsivo. Mi notevault de Obsidian está lleno de notas sobre los libros que leo, los que quiero leer y los que tengo a medias. Siempre he usado una nota simple en Markdown con una query de Dataview para llevar la cuenta, algo así:
TABLE author, Rating, genre
FROM "2-Areas/Personal/books"
Funcional, sí. Pero soso de cojones.
Siendo como soy, un yonqui de los datos, me picaba la curiosidad: ¿cuántas páginas he leído este año? ¿Cuál es mi autor favorito? ¿Leo más ficción o no ficción? ¿Tardo más en leer en español o en inglés?
La respuesta a estas preguntas no estaba en una simple tabla de Dataview. La respuesta estaba en hacer lo que más me gusta: coger un montón de datos crudos, procesarlos con Python y visualizarlos con Power BI hasta que canten.
Así que me propuse un mini-proyecto de fin de año: crear un dashboard interactivo para analizar mis lecturas de 2025.
Paso 1: Exportar los Datos de Obsidian
Lo primero era sacar los datos de mi vault. Obsidian es la leche, pero no está pensado para el análisis de datos. Por suerte, como todo está en archivos de texto plano (.md), es muy fácil de procesar.
Para poblar mi vault con información de libros, utilizo un plugin fantástico llamado Book Search. Este plugin me permite buscar libros (normalmente por ISBN o título) e importa automáticamente todos los metadatos relevantes (autor, páginas, editorial, portada, etc.) directamente en el frontmatter de la nota. Esto me ahorra muchísimo tiempo y asegura que los datos sean consistentes.
Cada libro es una nota en la carpeta Areas/Personal/books y usa un YAML frontmatter (gracias a mi plantilla y al plugin) para las propiedades clave:
---
title: "Elantris"
autor: "Brandon Sanderson"
genero: ["Fantasía", "Ciencia Ficción"]
paginas: 704
fecha_inicio: 2025-03-15
fecha_fin: 2025-04-02
puntuacion: 5
idioma: "Español"
---
## Notas y Resumen
...
Con esta estructura, escribir un script en Python para recorrer la carpeta, leer el frontmatter de cada archivo y volcarlo todo en un CSV es pan comido.
import os
import re
import csv
def extract_book_data_to_csv():
"""
Recorre todos los archivos markdown de libros en un directorio y extrae los datos
a un único archivo CSV.
"""
# Ajusta esta ruta a donde tengas tus libros
books_dir = "../../2-Areas/Personal/books"
output_csv_path = "books_data.csv"
if not os.path.isdir(books_dir):
print(f"Error: No se encuentra el directorio en {books_dir}")
return
# Cabeceras que esperamos encontrar y escribir en el CSV
headers = [
"filename", "title", "author", "category", "totalPage", "isbn13", "publisher", "Leido", "Rating"
]
all_books_data = []
# Regex para capturar el frontmatter YAML
yaml_frontmatter_pattern = re.compile(r"---\n(?P<frontmatter>.*?)\n---", re.DOTALL)
for filename in os.listdir(books_dir):
if filename.endswith(".md"):
file_path = os.path.join(books_dir, filename)
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
book_data = {"filename": filename}
# Intentar parsear el frontmatter YAML primero
frontmatter_match = yaml_frontmatter_pattern.search(content)
if frontmatter_match:
frontmatter_str = frontmatter_match.group("frontmatter")
# Parsear pares clave-valor del frontmatter
for line in frontmatter_str.split('\n'):
line = line.strip()
if ":" in line:
key, value = line.split(":", 1)
key = key.strip()
value = value.strip()
# Limpieza básica de valores
if key == "category":
value = value.replace("- ", "").replace("[", "").replace("]", "").strip()
if key in headers:
book_data[key] = value
all_books_data.append(book_data)
# Escribir los datos al archivo CSV
try:
with open(output_csv_path, 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=headers)
writer.writeheader()
writer.writerows(all_books_data)
print(f"¡Datos extraídos con éxito a {output_csv_path}!")
except IOError as e:
print(f"Error escribiendo el archivo CSV: {e}")
if __name__ == "__main__":
extract_book_data_to_csv()
Este script me genera un mis_libros_2025.csv listo para ser analizado.
Paso 2: Limpieza y Enriquecimiento de Datos en Power BI
Ahora empieza la fiesta de verdad. Para crear este dashboard, decidí probar algo nuevo: Claude Desktop junto con un servidor MCP (Model Context Protocol) para Power BI. Esta combinación me permitió interactuar con el modelo de datos de Power BI directamente desde Claude, agilizando enormemente el proceso de creación de medidas y transformaciones.
Al principio, mi modelo era una tabla plana con 111 libros y sin ninguna lógica de negocio. Para profesionalizarlo, apliqué varias mejoras críticas:
1. Organización: La Tabla de "Medidas"
Siguiendo las mejores prácticas de Power BI, creé una tabla calculada vacía llamada Medidas para centralizar toda la lógica DAX, separándola de la tabla de datos crudos (books_data).
2. Transformaciones de Datos (Power Query)
Hice limpieza directamente en el origen:
- Ocultar columnas técnicas: Como
isbn13ofilename, que ensucian el panel de campos. - Formatear datos: Configuré la columna
totalPagecon el formato#,0 "páginas". - Tratamiento del Rating: Como mis notas de Obsidian usan emojis (⭐⭐⭐) para la puntuación, tuve que crear una lógica para convertir eso en números.
3. Lógica DAX: Haciendo que los datos hablen
Creé un total de 12 medidas DAX. Aquí algunas de las más interesantes:
- Rating Promedio: Como el rating es una cadena de estrellas, calculo el promedio basándome en su longitud:
Rating Promedio = AVERAGEX( FILTER(books_data, books_data[Rating] <> BLANK()), LEN(books_data[Rating]) ) - Porcentaje de Lectura: Para saber qué parte de mi biblioteca he completado realmente:
% Libros Leídos = DIVIDE([Libros Leídos], [Total Libros], 0) - Top Autor: Una medida dinámica para identificar automáticamente a mi autor más leído:
Top Autor = VAR TopAuthorTable = TOPN( 1, SUMMARIZE(books_data, books_data[author], "LibrosCount", [Total Libros]), [LibrosCount], DESC ) RETURN MAXX(TopAuthorTable, books_data[author])

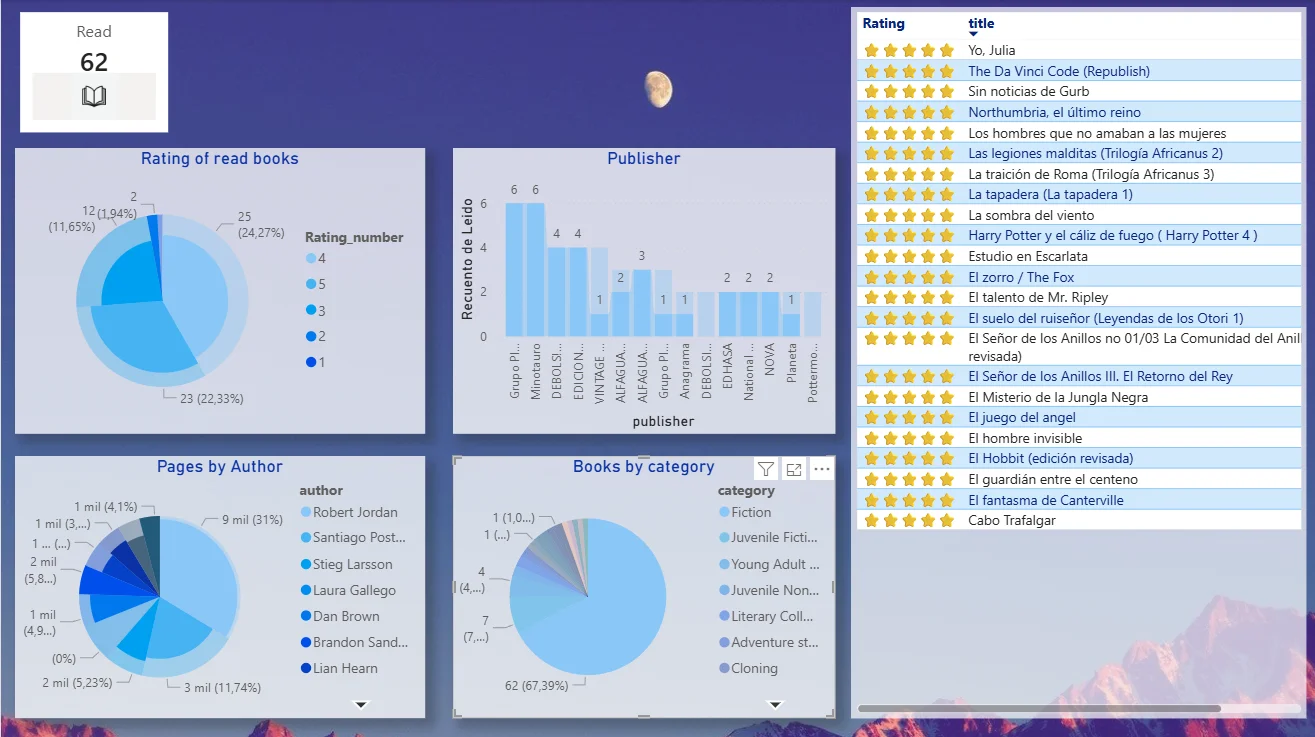
Paso 3: Creando las Visualizaciones
Con los datos limpios y listos, llegó el momento de "pintar". Arrastrar y soltar.
Creé varias visualizaciones:
- KPIs Principales: Tarjetas grandes y claras con el Número total de libros leídos, Total de páginas y Puntuación media.
- Libros leídos por Mes: Un gráfico de barras para ver mis picos de lectura. ¿Leí más en vacaciones? ¿O en los meses de más curro?
- Distribución por Género: Un gráfico de anillos (o donut chart, que suena más guay) para ver qué géneros domino. Spoiler: la fantasía gana por goleada.
- Top Autores: Una tabla simple mostrando los autores que más he leído.
- Correlación Páginas vs. Puntuación: Un gráfico de dispersión para responder a la eterna pregunta: ¿los libros más largos son mejores? (Parece que no hay una relación clara).
Conclusiones de un Año de Lectura
El resultado es un dashboard que no solo es bonito, sino que me cuenta una historia sobre mis hábitos como lector.
- He descubierto que mi ritmo de lectura baja drásticamente en verano (demasiadas birras, supongo).
- Brandon Sanderson es, oficialmente, el dueño de mi año lector.
- Aunque me flipa la ciencia ficción, leo mucha más fantasía.
Este proyecto es el ejemplo perfecto de cómo puedes aplicar tus habilidades técnicas a tus hobbies personales. Cuesta un poco montarlo, pero el resultado es una herramienta de autoconocimiento brutalmente divertida. Si llevas un registro de tus lecturas, te animo a que intentes algo parecido. Quizás te sorprendas de lo que tus datos dicen de ti.